

Amazon Redshift already provides up to 3x better price-performance at any scale than any other cloud data warehouse. We do this by designing our own hardware and by using Machine Learning (ML).
For example, we launched the SSD-based RA3 nodes for Amazon Redshift at the end of 2019 (Amazon Redshift Update – Next-Generation Compute Instances and Managed, Analytics-Optimized Storage) and added additional node sizes last April (Amazon Redshift update – ra3.4xlarge Nodes), and last December (Amazon Redshift Launches RA3.xlplus Nodes With Managed Storage). In addition to high-bandwidth networking, RA3 nodes incorporate a sophisticated data management model. As I said when we launched the RA3 nodes:
There’s a cache of large-capacity, high-performance SSD-based storage on each instance, backed by S3, for scale, performance, and durability. The storage system uses multiple cues, including data block temperature, data blockage, and workload patterns, to manage the cache for high performance. Data is automatically placed into the appropriate tier, and you need not do anything special to benefit from the caching or the other optimizations.
Our customers use RA3 nodes to maintain very large data sets and are seeing great results. From digital interactive entertainment to tracking impressions and performance for media buys, Amazon Redshift and RA3 nodes help our customers to store and query data at world scale, with up to 32 PB of data in a single data warehouse.
On the downside, it turns out that advances in storage performance have outpaced those in CPU performance, even as data warehouses continue to grow. The combination of large amounts of data (often accessed by queries that mandate a full scan), and limits on network traffic, can result in a situation where network and CPU bandwidth become limiting factors.
We can do something about that…
Introducing AQUA
Today we are making the ra3.4xl and ra3.16xl nodes even more powerful with the addition of AQUA (Advanced Query Accelerator). Building on the caches that I told you about earlier, and taking advantage of the AWS Nitro System and custom FPGA-based acceleration, AQUA pushes the computation needed to handle reduction and aggregation queries closer to the data. This reduces network traffic, offloads work from the CPUs in the RA3 nodes, and allows AQUA to improve the performance of those queries by up to 10x, at no extra cost and without any code changes. AQUA also makes use of a fast, high-bandwidth connection to Amazon Simple Storage Service (S3).
You can watch this video to learn a lot more about how AQUA uses the custom-designed hardware in the AQUA nodes to accelerate queries. The benefit comes about in several different ways. Each node performs the reduction and aggregation operations in parallel with the others. In addition to getting the n-fold speedup due to parallelism, the amount of data that must be sent to and processed on the compute nodes is generally far smaller (often just 5% of the original). Here’s a diagram that shows how all of the elements come together to accelerate queries:
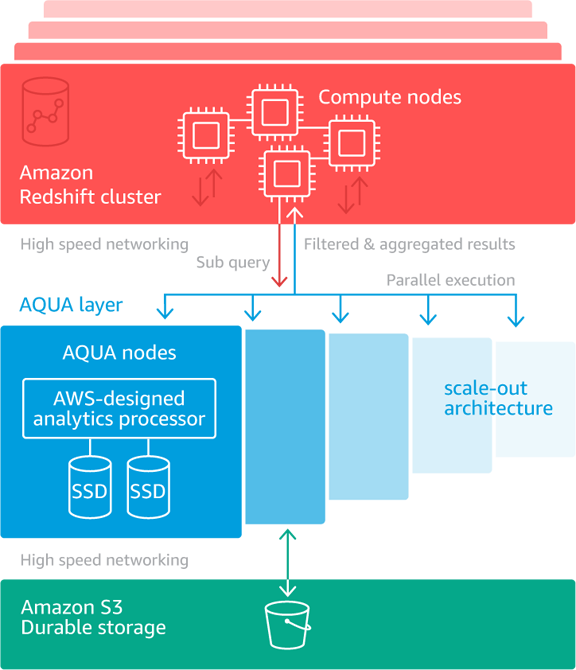
If you are already using ra3.4xl or ra3.16xl nodes to host your data warehouse, you can start using AQUA in minutes. You simply enable AQUA for your clusters, restart them, and benefit from vastly improved performance for your reduction and aggregation queries. If you are ready to move into the future with RA3 and AQUA, you can create a new RA3-based cluster from a snapshot of your existing one, or you can use Classic resize to do an in-place upgrade.
Using AQUA
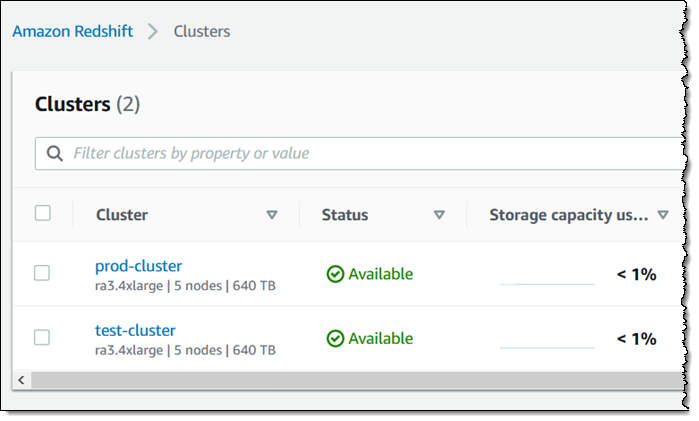
I don’t happen to have a data warehouse! I used a snapshot provided by the Redshift team to create a pair of clusters. The first one (prod-cluster) does not have AQUA enabled, and the second one (test-cluster) does:
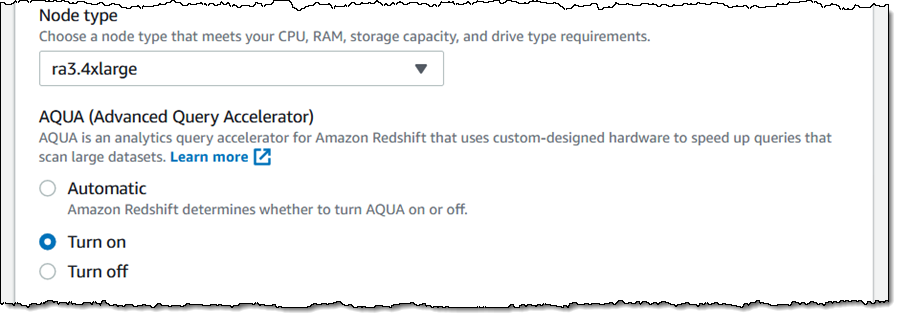
To create the AQUA-enabled cluster, I simply choose Turn on on the Cluster configuration page:
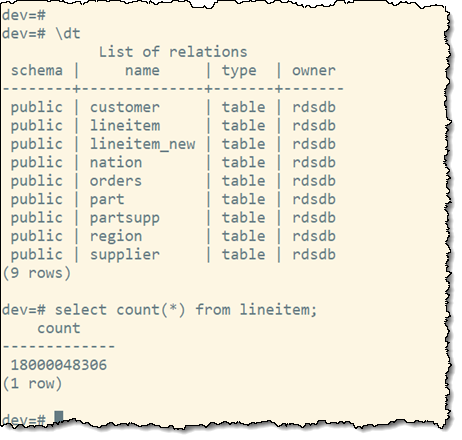
My queries will use the lineitem table, which has over 18 billion rows:
I create a session on each cluster and disable the Redshift result cache:
And then I run the same query on both clusters:
If you take a look at the diagram above (and perhaps watch the video), you can see why AQUA can handle queries of this type very efficiently. Instead of sequentially scanning all 18 billion or so rows on the compute nodes, AQUA distributes the collection of similar to expressions to multiple AQUA nodes where they are run in parallel.
The query on the cluster that has AQUA enabled finishes in less than a minute:
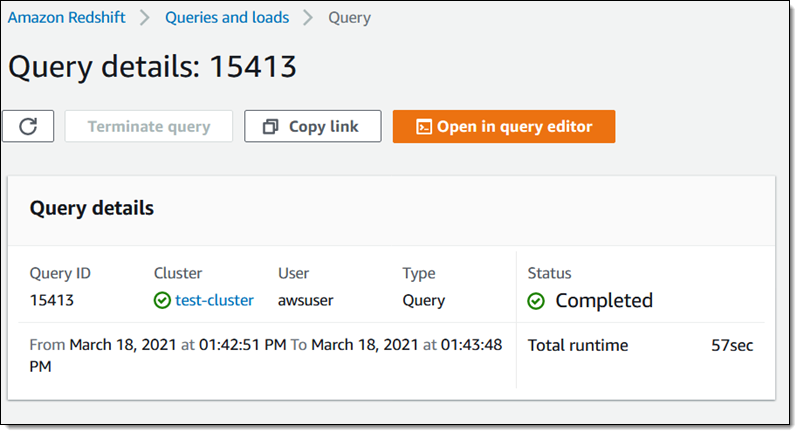
The query on the cluster that does not have AQUA enabled finishes in a little under 4 minutes:
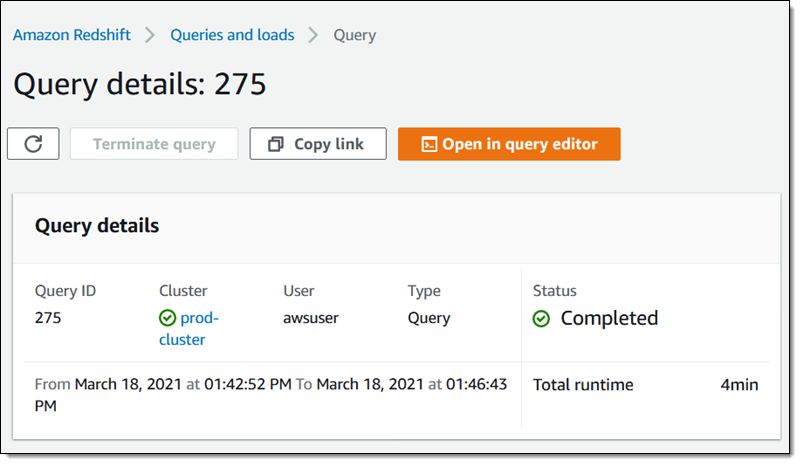
As is always the case with databases, complex data, and equally complex queries, your mileage will vary. For example, you could imagine a query that did a complex JOIN of rows SELECTed from multiple tables, where each SELECT would benefit from AQUA, and the overall speedup could be even greater. As you can see from the simple query that I used for this post, AQUA can dramatically reduce query time and perhaps even enable some new types of somewhat real-time queries that were simply not possible or practical in the past.
Things to Know
Here are a couple of interesting facts about AQUA:
Cluster Version – Your clusters must be running Redshift version 1.0.24421 or later in order to be able to make use of AQUA. To learn more about how to enable and disable AQUA, read Managing an AQUA Cluster.
Relevant Queries – AQUA is designed to deliver up to 10X performance on queries that perform large scans, aggregates, and filtering with LIKE and SIMILAR_TO predicates. Over time we expect to add support for additional queries.
Security – All data cached by AQUA is encrypted using your keys. After performing a filtering or aggregation operation, AQUA compresses the results, encrypts them, and returns them to Redshift.
Regions – AQUA is available today in the US East (N. Virginia), US West (Oregon), US East (Ohio), Europe (Ireland), and Asia Pacific (Tokyo) Regions, and will be coming to Europe (Frankfurt), Asia Pacific (Sydney), and Asia Pacific (Singapore) in the first half of 2021.
Pricing – As I mentioned earlier, there’s no additional charge for AQUA.
Try AQUA Today
If you are using ra3.4xl or ra3.16xl nodes to power your Redshift cluster, you can enable AQUA, restart the cluster, and run some test queries within minutes. Take AQUA for a spin and let me know what you think!
— Jeff;












