

Source is Amazon Business Productivity
Why is it useful to label speakers on conference calls?
In many multi-party voice communications use cases, it is important to identify and label the active speakers in real time, in order to know what was said and by whom. This information is also valuable after the call, for identity attribution in transcripts. In this post, we will demonstrate the use of Amazon Chime SDK call analytics, and its speaker search capability, to attach speaker identity labels to calls in real time, and for post-call insights.
There are many real-world use cases for such a multi-speaker labeling capability. For example:
- to transcribe executives on an earnings call and label the transcript with “who said what”
- to identify and label the active speaker in real time on a squawk box communication platform used by traders
What is speaker search?
Speaker search is a new machine-learning-powered capability that is part of Amazon Chime SDK call analytics. It provides the ability to takes a short speech sample from call audio and return a set of closest matches from a database of voice embeddings, or voice profiles, for enrolled speakers. This capability is available through speaker search APIs for Amazon Chime SDK Voice Connector.
Solution overview
In this simple demonstration, we will periodically call speaker search over the duration of a conversation, and show how it can be used to label the different speakers active during a conversation.
For the purpose of this demonstration, we assembled four AWS employees (“Alice”, “Bob”, “Charlie” and “David”) in a room with a speaker phone that was dialed in to a phone number associated with a Voice Connector. For the callee in this demo, we used an Asterisk server running an automated agent response system. We applied speaker search to the caller leg only (containing the four volunteers). All four volunteers had previously enrolled their voice embeddings by providing a short voice sample, and, importantly, all four volunteers consented to the creation and processing of their voice embedding as required by applicable privacy and biometric laws and as a condition of using the service (for more information please see section 53 of the AWS Service Terms).
In the demo, we used a script to trigger speaker search API calls to the voice analytics service approximately every 30 seconds (with a sample of approximately 10 seconds of silence-free speech for each API call), and logged the speaker search results to an SNS notification target configured for this Voice Connector. The speakers spoke sequentially for roughly two minutes each.
When the speaker search API is called using an inference speech sample, it generates an embedding, which is a vector representation that captures some of the distinguishing attributes of the speaker’s voice. This embedding is compared to the embeddings for all the enrolled speakers in the embeddings database, and a shortlist of up to 10 highest confidence matches are returned, ranked in order of a confidence score. For the purpose of this demo, we retained only the highest confidence match and used that as our estimate for who is speaking.
Results
The audio recording for the session is shown below along with annotations of the estimated speaker identity as well as the true speaker identity. Comparing the estimate to the ground truth over the duration of the call, we obtain an accuracy score, defined as the percentage of searches for which the estimated identity matched the true speaker identity.
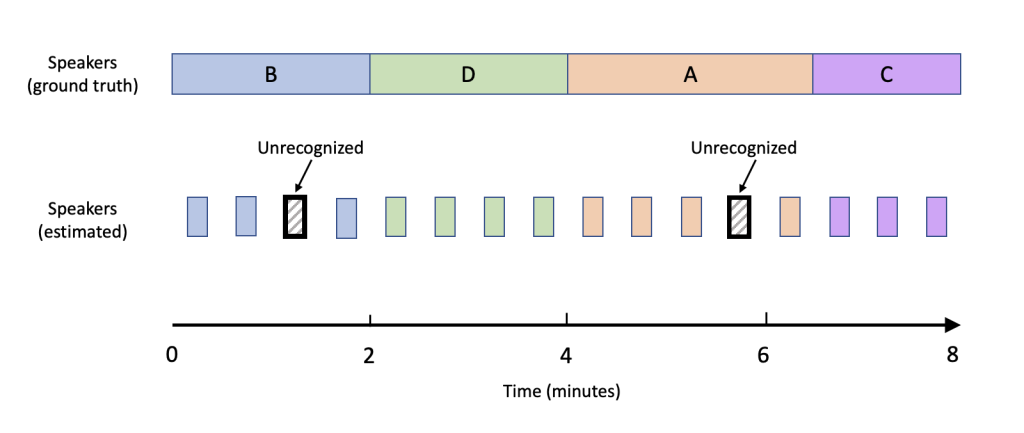
The accuracy score for this demonstration was 88%. Speaker search accurately identified the speaker during most of the segments with a few exceptions, where the speaker was not recognized as a match with a high-enough confidence level to exceed our preset threshold.
This test demonstrates that even a simple implementation such as the above can help address speaker labelling use cases. There are many ways to improve the labeling accuracy such as:
- increasing the frequency of the speaker search API calls
- tuning the inference speech sample length
- tuning the match confidence threshold
- using the Amazon Transcribe integration to extract speaker endpoints which partition the utterances, and run speaker search queries against those partitioned utterances.
Get started with Amazon Chime SDK call analytics and speaker search
- First, you will need to configure an Amazon Chime SDK Voice Connector with a call analytics configuration with voice analytics enabled (including creating a voice profile domain, and creating a set of notification targets to receive speaker search results), and you will need to configure a speaker search workflow. See the Amazon Chime SDK Developer Guide for details.
- To use the speaker search feature, you will need to open an SLI ticket. See here for how to request a quota increase.
Learn More
To learn more about Amazon Chime SDK voice analytics, review the following resources:











